|
|
ParaMonte Fortran 2.0.0
Parallel Monte Carlo and Machine Learning Library
See the latest version documentation. |
|
|
ParaMonte Fortran 2.0.0
Parallel Monte Carlo and Machine Learning Library
See the latest version documentation. |

This module contains procedures and generic interfaces for computing sum(x) accurately when x is a long array of wildly varying real or complex values.
More...
Data Types | |
| type | fablocked_type |
| This is a concrete derived type whose instances are exclusively used to request the Fast Accurate Blocked summation method of Blanchard, Higham, and Mary, 2020 within the generic interfaces of the ParaMonte library. More... | |
| interface | getDot |
Generate and return the expression dot_product(x, y) accurately (almost without roundoff error).More... | |
| interface | getSum |
Generate and return the expression sum(x) accurately (almost without roundoff error).More... | |
| type | kahanbabu_type |
| This is a concrete derived type whose instances are exclusively used to request the Kahan-Babuska summation method within the generic interfaces of the ParaMonte library. More... | |
| type | nablocked_type |
| This is a concrete derived type whose instances are exclusively used to request the Naive Blocked summation method of Blanchard, Higham, and Mary, 2020 within the generic interfaces of the ParaMonte library. More... | |
| type | sum_type |
Variables | |
| character(*, SK), parameter | MODULE_NAME = "@pm_mathSum" |
| type(fablocked_type), parameter | fablocked = fablocked_type() |
This is a scalar parameter object of type fablocked_type.More... | |
| type(nablocked_type), parameter | nablocked = nablocked_type() |
This is a scalar parameter object of type nablocked_type.More... | |
| type(kahanbabu_type), parameter | kahanbabu = kahanbabu_type() |
This is a scalar parameter object of type kahanbabu_type.More... | |
This module contains procedures and generic interfaces for computing sum(x) accurately when x is a long array of wildly varying real or complex values.
Some of the algorithms of this module are inspired by the work of Blanchard, Higham, and Mary, 2020, A Class of Fast and Accurate Summation Algorithms.
Benchmark :: The effects of method on runtime efficiency ⛓
sum() intrinsic function.
Example Unix compile command via Intel ifort compiler ⛓
Example Windows Batch compile command via Intel ifort compiler ⛓
Example Unix / MinGW compile command via GNU gfortran compiler ⛓
Postprocessing of the benchmark output ⛓
Visualization of the benchmark output ⛓
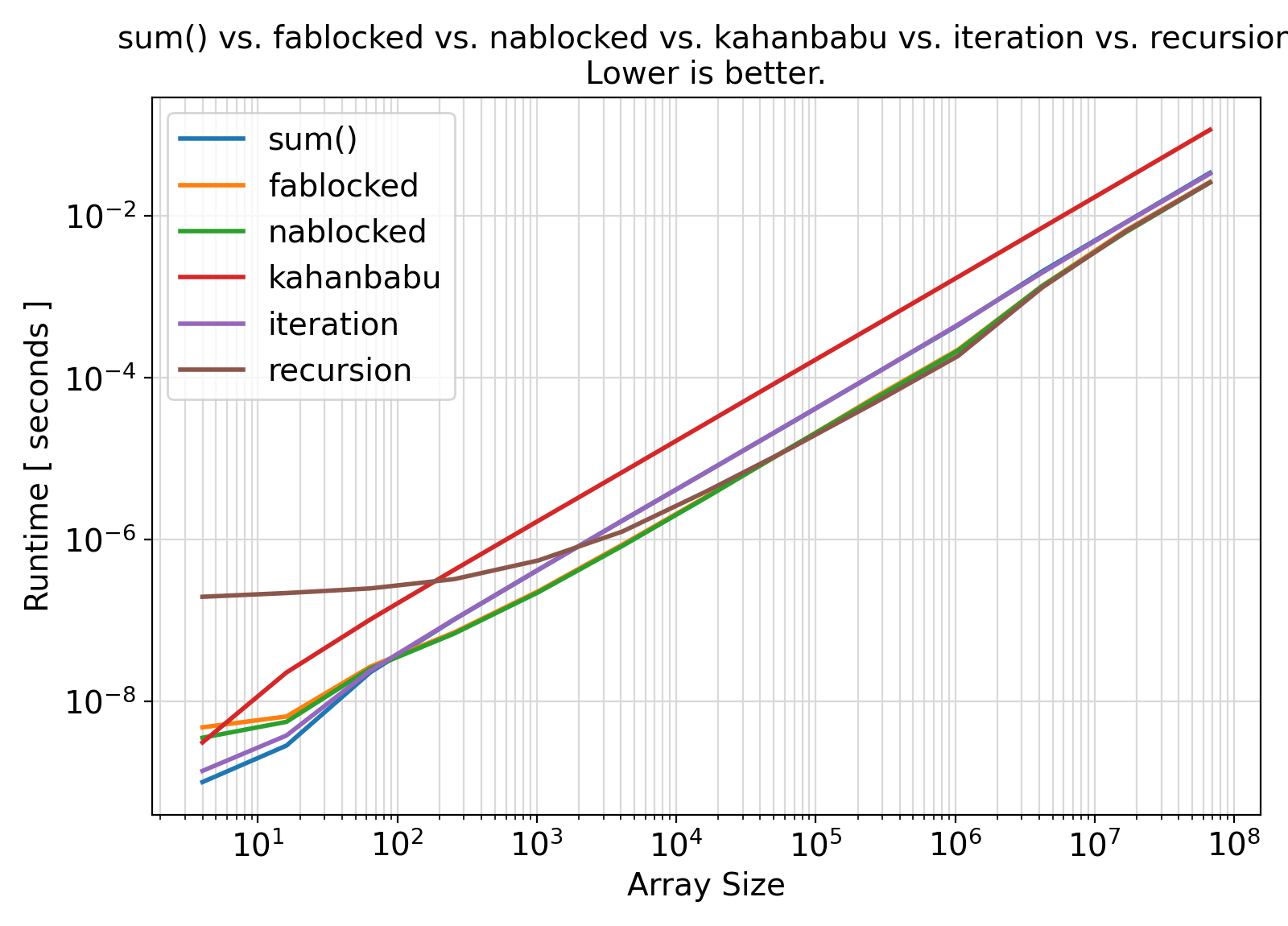
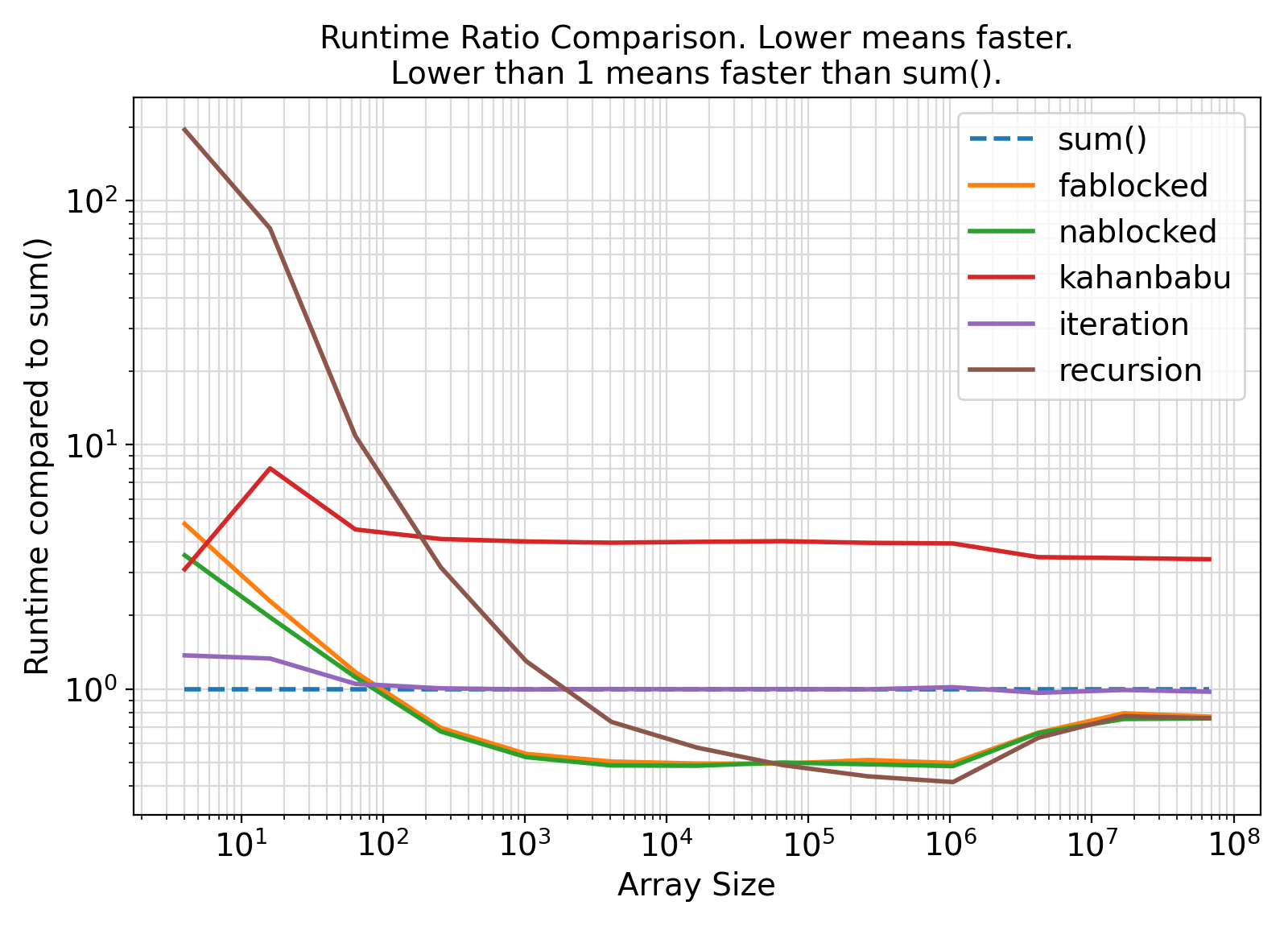
Benchmark moral ⛓
sum() and all other implemented summation algorithms for array sizes > 100.
Benchmark :: The effects of method on runtime efficiency ⛓
dot_product() intrinsic function.
Example Unix compile command via Intel ifort compiler ⛓
Example Windows Batch compile command via Intel ifort compiler ⛓
Example Unix / MinGW compile command via GNU gfortran compiler ⛓
Postprocessing of the benchmark output ⛓
Visualization of the benchmark output ⛓
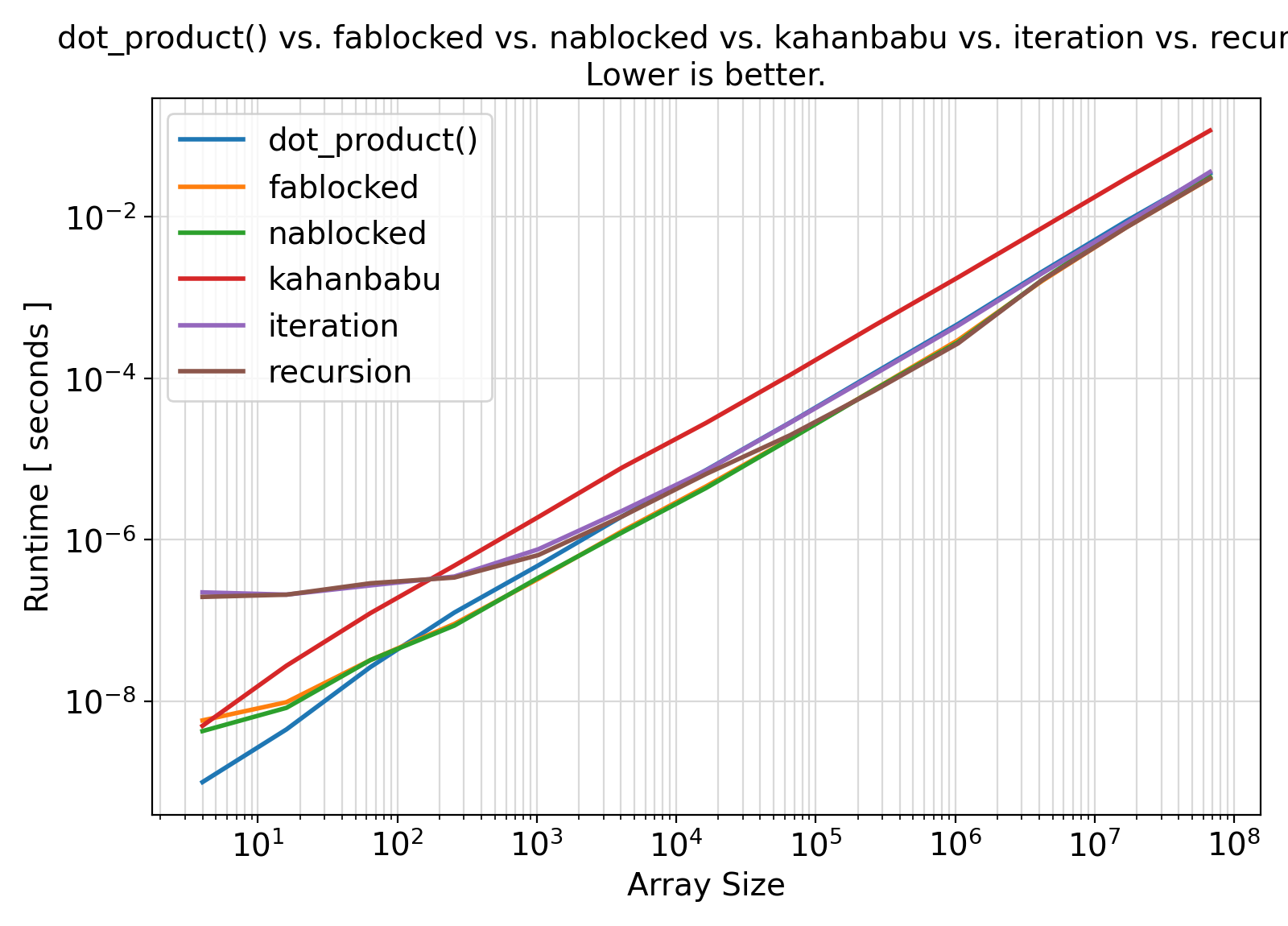
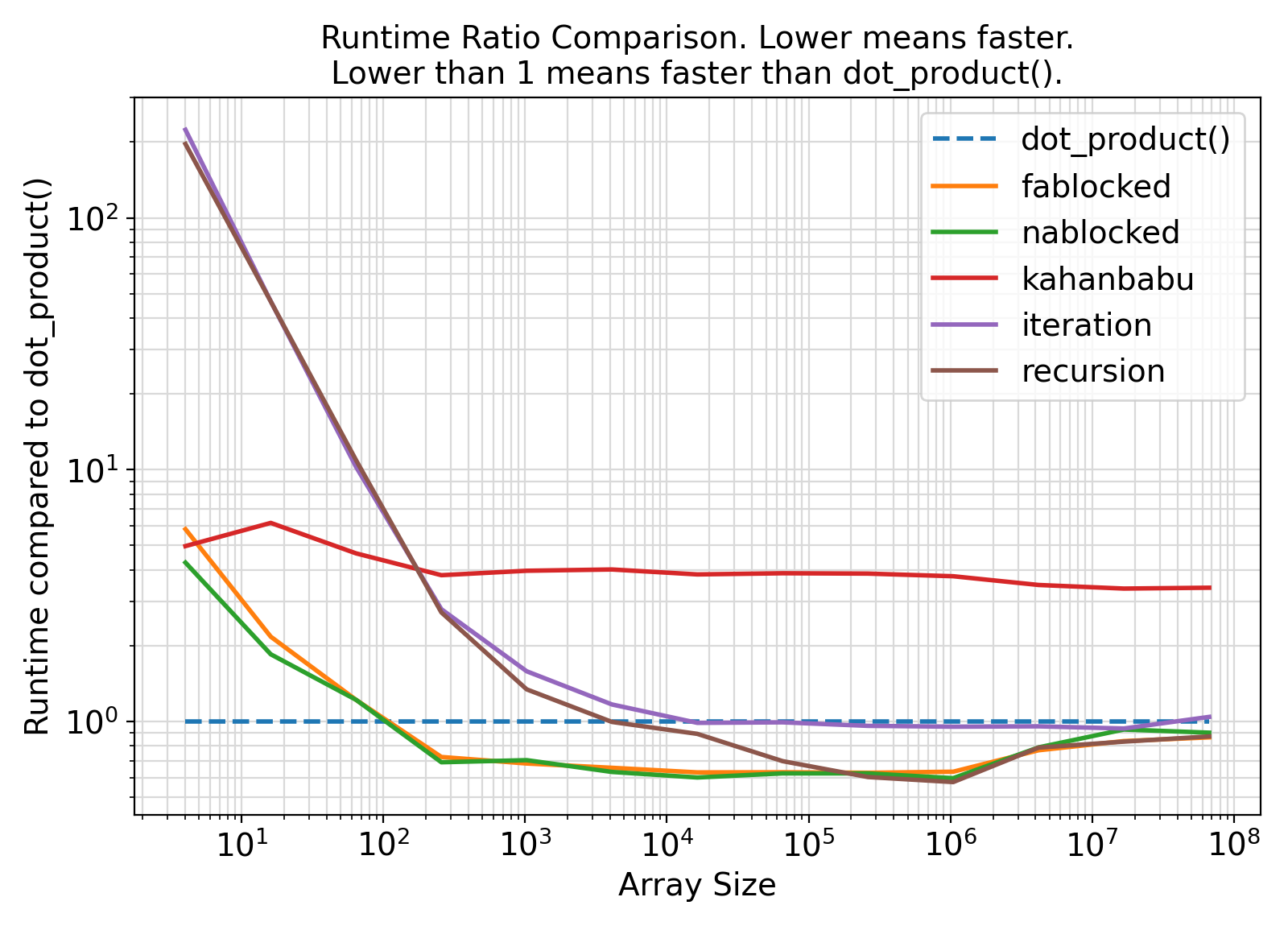
Benchmark moral ⛓
dot_product() and all other implemented summation algorithms for array sizes > 100.
Final Remarks ⛓
If you believe this algorithm or its documentation can be improved, we appreciate your contribution and help to edit this page's documentation and source file on GitHub.
For details on the naming abbreviations, see this page.
For details on the naming conventions, see this page.
This software is distributed under the MIT license with additional terms outlined below.
This software is available to the public under a highly permissive license.
Help us justify its continued development and maintenance by acknowledging its benefit to society, distributing it, and contributing to it.
| type(fablocked_type), parameter pm_mathSum::fablocked = fablocked_type() |
This is a scalar parameter object of type fablocked_type.
For example usage, see the documentation of the target procedure requiring this object.
Final Remarks ⛓
If you believe this algorithm or its documentation can be improved, we appreciate your contribution and help to edit this page's documentation and source file on GitHub.
For details on the naming abbreviations, see this page.
For details on the naming conventions, see this page.
This software is distributed under the MIT license with additional terms outlined below.
This software is available to the public under a highly permissive license.
Help us justify its continued development and maintenance by acknowledging its benefit to society, distributing it, and contributing to it.
Definition at line 143 of file pm_mathSum.F90.
| type(kahanbabu_type), parameter pm_mathSum::kahanbabu = kahanbabu_type() |
This is a scalar parameter object of type kahanbabu_type.
For example usage, see the documentation of the target procedure requiring this object.
Final Remarks ⛓
If you believe this algorithm or its documentation can be improved, we appreciate your contribution and help to edit this page's documentation and source file on GitHub.
For details on the naming abbreviations, see this page.
For details on the naming conventions, see this page.
This software is distributed under the MIT license with additional terms outlined below.
This software is available to the public under a highly permissive license.
Help us justify its continued development and maintenance by acknowledging its benefit to society, distributing it, and contributing to it.
Definition at line 266 of file pm_mathSum.F90.
| character(*, SK), parameter pm_mathSum::MODULE_NAME = "@pm_mathSum" |
Definition at line 80 of file pm_mathSum.F90.
| type(nablocked_type), parameter pm_mathSum::nablocked = nablocked_type() |
This is a scalar parameter object of type nablocked_type.
For example usage, see the documentation of the target procedure requiring this object.
Final Remarks ⛓
If you believe this algorithm or its documentation can be improved, we appreciate your contribution and help to edit this page's documentation and source file on GitHub.
For details on the naming abbreviations, see this page.
For details on the naming conventions, see this page.
This software is distributed under the MIT license with additional terms outlined below.
This software is available to the public under a highly permissive license.
Help us justify its continued development and maintenance by acknowledging its benefit to society, distributing it, and contributing to it.
Definition at line 206 of file pm_mathSum.F90.

