This module contains procedures and generic interfaces relevant to combined matrix-matrix or matrix-vector multiplication and addition.
More...
This module contains procedures and generic interfaces relevant to combined matrix-matrix or matrix-vector multiplication and addition.
The procedures under the generic interface setMatMulAdd of this module return the result of the multiplication of the input matrices matA and matB in one of the following forms,
\begin{align*}
& \ms{matC} \leftarrow \alpha \ms{matA}~~ \ms{matB} + \beta \ms{matC} && \ms{matC} \leftarrow \alpha \ms{matA}~~ \ms{matB}^T + \beta \ms{matC} && \ms{matC} \leftarrow \alpha \ms{matA}~~ \ms{matB}^H + \beta \ms{matC} \\
& \ms{matC} \leftarrow \alpha \ms{matA}^T \ms{matB} + \beta \ms{matC} && \ms{matC} \leftarrow \alpha \ms{matA}^T \ms{matB}^T + \beta \ms{matC} && \ms{matC} \leftarrow \alpha \ms{matA}^T \ms{matB}^H + \beta \ms{matC} \\
& \ms{matC} \leftarrow \alpha \ms{matA}^H \ms{matB} + \beta \ms{matC} && \ms{matC} \leftarrow \alpha \ms{matA}^H \ms{matB}^T + \beta \ms{matC} && \ms{matC} \leftarrow \alpha \ms{matA}^H \ms{matB}^H + \beta \ms{matC}
\end{align*}
where \(\cdot^T\) represents a Symmetric transpose, \(\cdot^H\) represents a Hermitian transpose, and matA or matB can be also specified as Symmetric/Hermitian upper/lower triangular matrices.
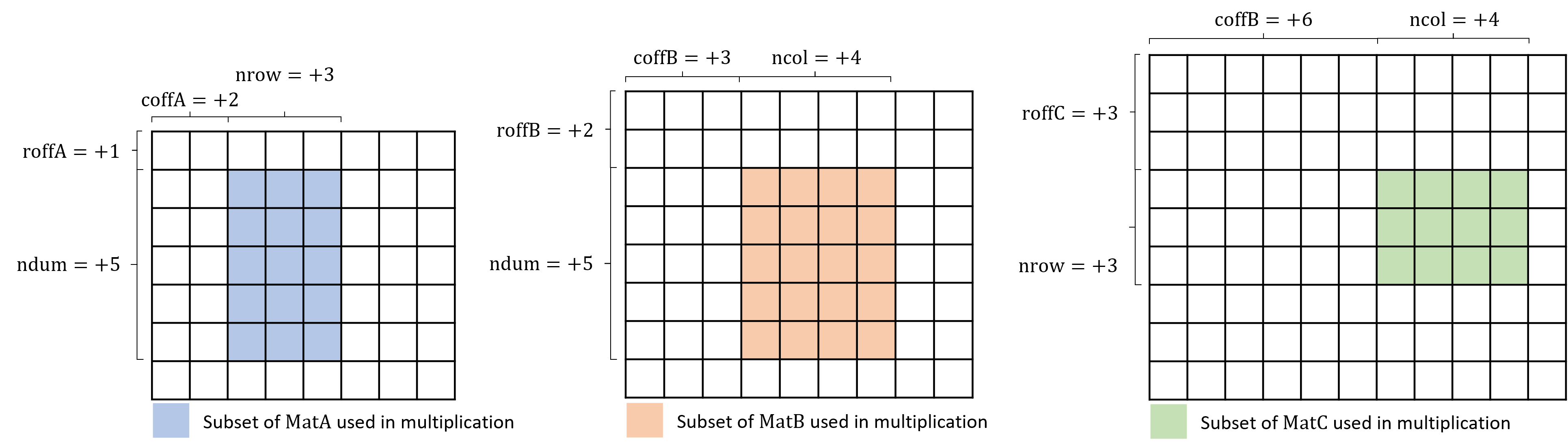
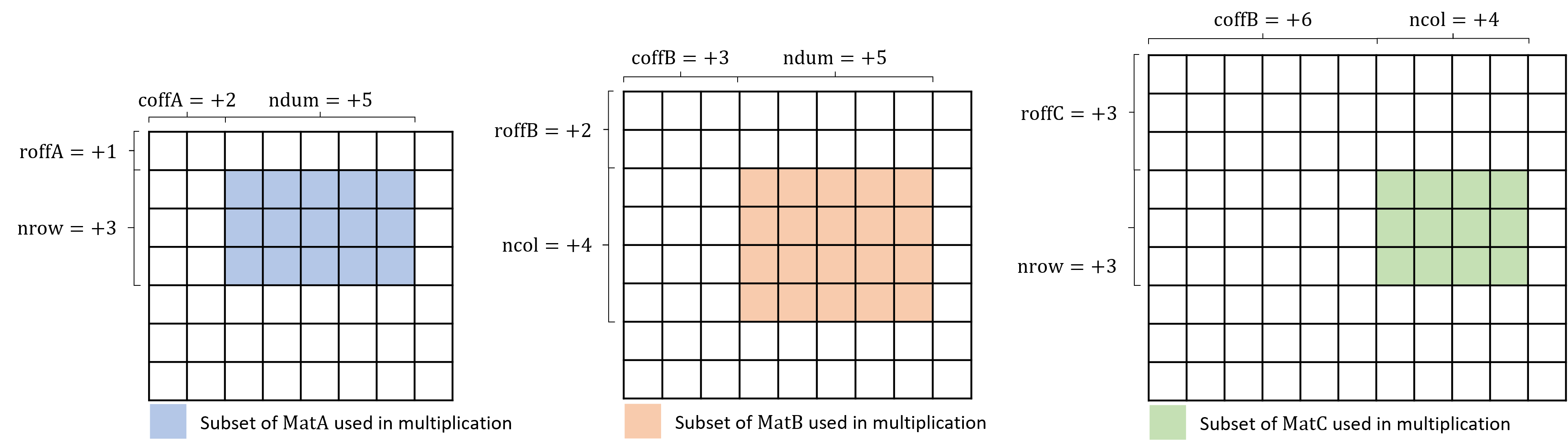
The following figure illustrates the form of the general matrix-matrix or matrix-vector multiplication depending on the input values.
-
Default Multiplication (no transposition involved).
-
Same as the default but with
operationA set to transSymm or transHerm.
-
Same as the default but with
operationB set to transSymm or transHerm.
For symmetric or Hermitian matrices, only the upper or lower triangles of the corresponding matrices are required and referenced.
Although the implementation is custom-defined for Symmetric/Hermitian matrices, the multiplication is defined as in the figure of case 1 above.
- Note
- For triangular matrix-matrix or matrix-vector multiplications, see pm_matrixMulTri.
- BLAS/LAPACK equivalent:
- The procedures under discussion combine, modernize, and extend the interface and functionalities of Version 3.11 of BLAS/LAPACK routine(s):
SAXPY, DAXPY, CAXPY, ZAXPY SGEMV, DGEMV, CGEMV, ZGEMV SSPMV, DSPMV, CHPMV, ZHPMV, SSYMV, DSYMV, CHEMV, ZHEMV, SGEMM, DGEMM, CGEMM, ZGEMM, SSYMM, DSYMM, CSYMM, ZSYMM, CHEMM, ZHEMM.
In particular multiplications of matrices of type integer of arbitrary kinds are also possible.
- See also
- lowDia
uppDia
symmetric
hermitian
transSymm
transHerm
setMatMulTri
- Benchmarks:
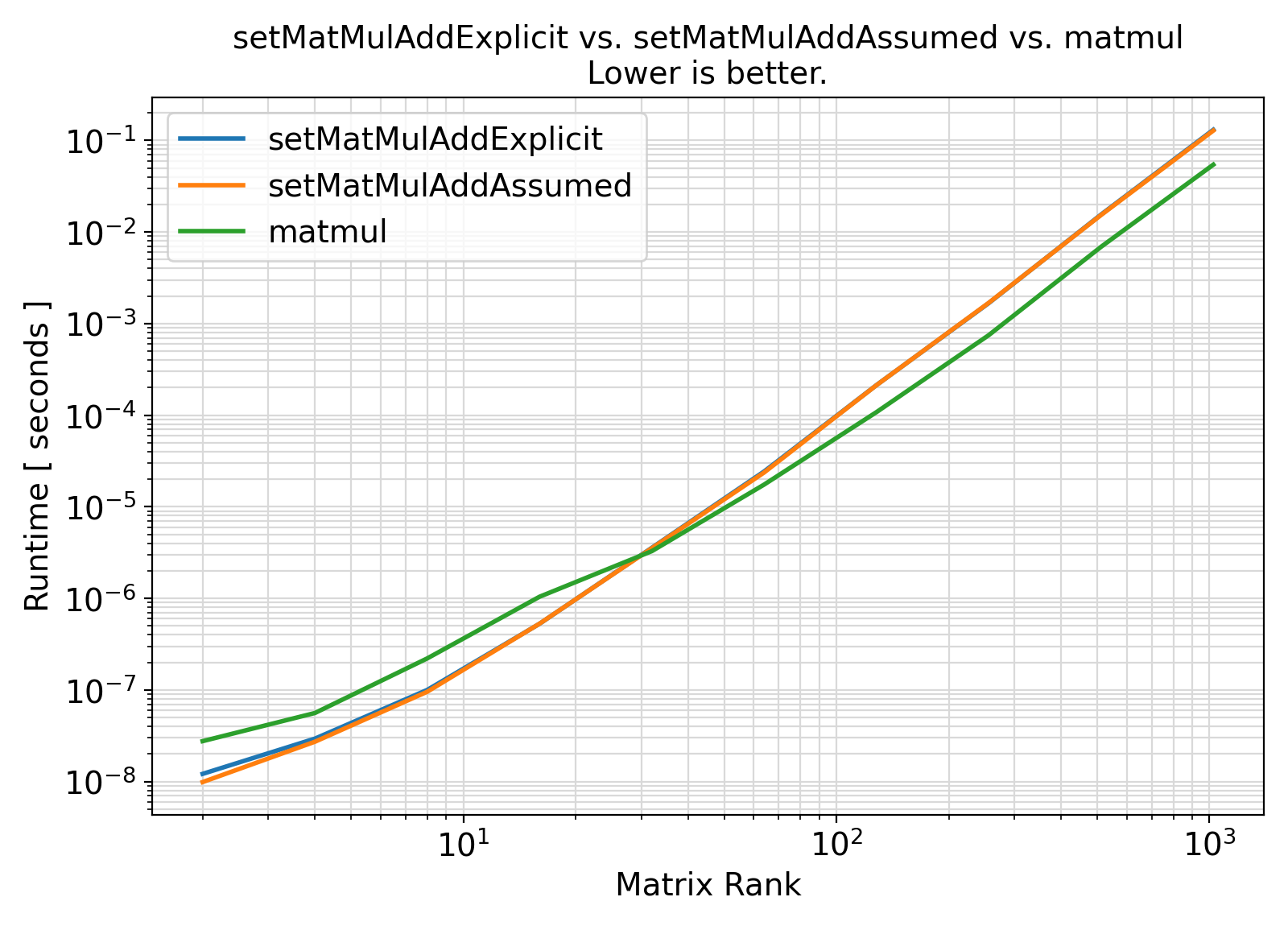
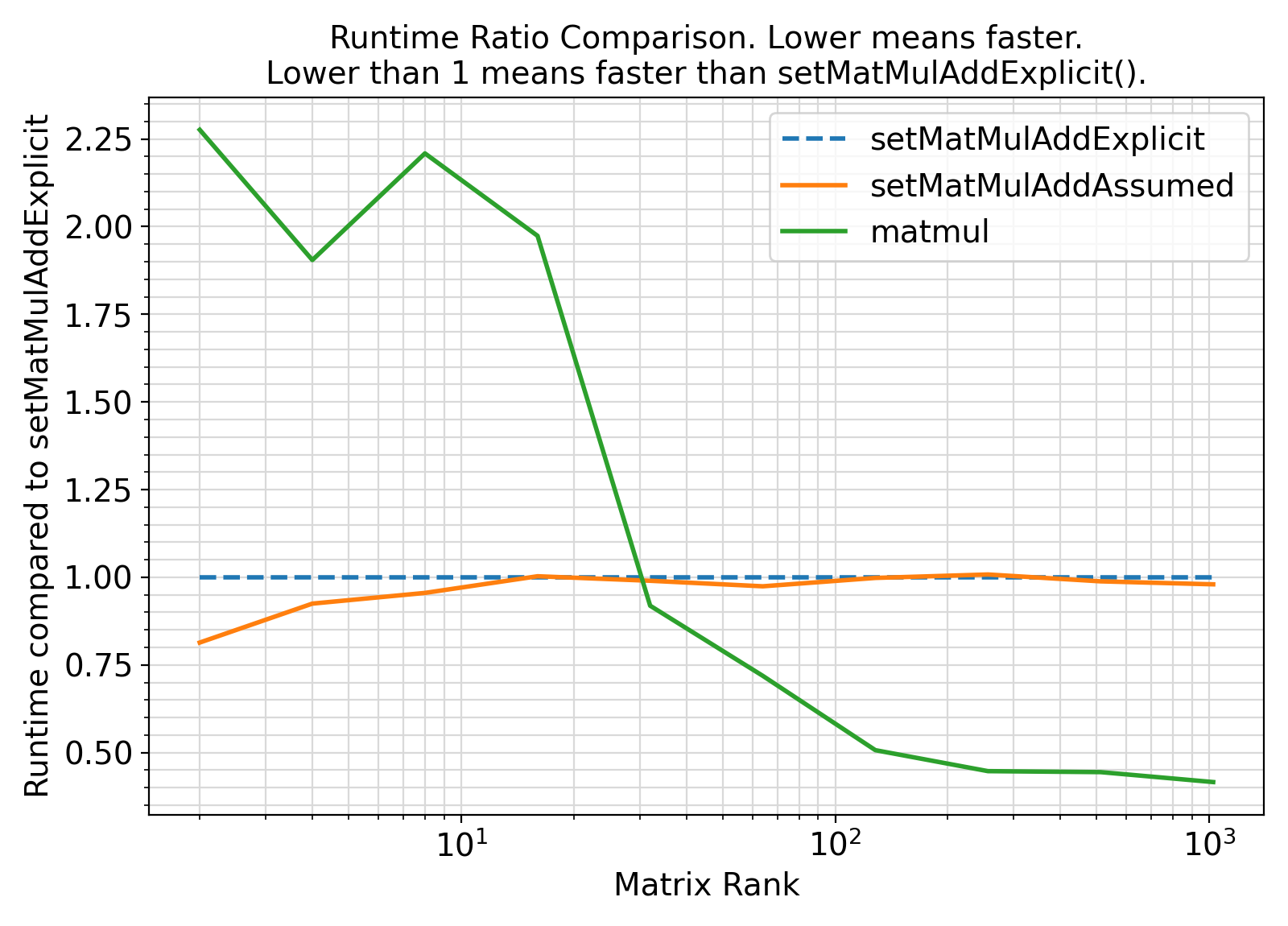
Benchmark :: The runtime performance of setMatMulAdd vs. other other approaches. ⛓
7 use iso_fortran_env,
only:
error_unit
13 integer(IK) :: itry, ntry
17 integer(IK) :: fileUnit
18 integer(IK) ,
parameter :: NUM_RANK
= 10_IK
19 integer(IK) ,
parameter :: MAX_RANK
= 2**NUM_RANK
20 integer(IK) ,
parameter :: MAX_ITER
= 10000
21 real(RKG) ,
parameter :: ALPHA
= 1._RKG
22 real(RKG) ,
parameter :: BETA
= 1._RKG
23 real(RKG) :: dummySum
= 0._RKG
24 real(RKG) , dimension(:,:),
allocatable :: matA, matB, matC
25 type(bench_type) ,
allocatable :: bench(:)
27 bench
= [
bench_type(name
= SK_
"setMatMulAddExplicit", exec
= setMatMulAddExplicit, overhead
= setOverhead)
&
28 ,
bench_type(name
= SK_
"setMatMulAddAssumed", exec
= setMatMulAddAssumed, overhead
= setOverhead)
&
29 ,
bench_type(name
= SK_
"matmul", exec
= setMatMulTri, overhead
= setOverhead)
&
31 ,
bench_type(name
= SK_
"GEMM", exec
= setBlasGEMM, overhead
= setOverhead)
&
35 write(
*,
"(*(g0,:,' '))")
36 write(
*,
"(*(g0,:,' '))")
"setMatMulAdd() vs. matmul() vs. GEMM()"
37 write(
*,
"(*(g0,:,' '))")
39 open(newunit
= fileUnit, file
= "main.out", status
= "replace")
40 write(fileUnit,
"(*(g0,:,', '))")
"Matrix Rank", (bench(ibench)
%name, ibench
= 1,
size(bench))
41 loopOverMatDiaRank:
do irank
= 1, NUM_RANK
44 ntry
= MAX_ITER
/ rank
45 write(
*,
"(*(g0,:,' '))")
"Benchmarking with rank:", rank
46 matA
= getMatInit([rank, rank], uppLowDia,
0._RKG,
0._RKG,
0._RKG);
47 matB
= getMatInit([rank, rank], uppLowDia,
0._RKG,
0._RKG,
0._RKG);
48 matC
= getMatInit([rank, rank], uppLowDia,
0._RKG,
0._RKG,
0._RKG);
51 call setMatMulAddExplicit()
52 call setMatMulAddAssumed()
58 do ibench
= 1,
size(bench)
59 bench(ibench)
%timing
= bench(ibench)
%getTiming(minsec
= 0.07_RKG)
61 write(fileUnit,
"(*(g0,:,', '))") rank
&
62 , (bench(ibench)
%timing
%mean
/ ntry, ibench
= 1,
size(bench))
64 end do loopOverMatDiaRank
65 write(
*,
"(*(g0,:,' '))")
sum(matC)
66 write(
*,
"(*(g0,:,' '))")
75 subroutine setOverhead()
82 dummySum
= dummySum
+ matC(
1,
1)
85 subroutine setMatMulAddExplicit()
87 call setMatMulAdd(matA, matB, matC, alpha, beta, rank, rank, rank,
0_IK,
0_IK,
0_IK,
0_IK,
0_IK,
0_IK)
92 subroutine setMatMulAddAssumed()
99 subroutine setMatMulTri()
101 matC
= alpha
* matmul(matA(
1:rank,
1:rank), matB(
1:rank,
1:rank))
+ beta
* matC(
1:rank,
1:rank)
107 subroutine setBlasGEMM()
Generate and return an object of type timing_type containing the benchmark timing information and sta...
Return a uniform random scalar or contiguous array of arbitrary rank of randomly uniformly distribute...
Generate and return a matrix of shape (shape(1), shape(2)) with the upper/lower triangle and the diag...
Return the result of the multiplication of the input matrices/vector matA and matB in the user-specif...
This module contains abstract interfaces and types that facilitate benchmarking of different procedur...
This module contains classes and procedures for computing various statistical quantities related to t...
This module defines the relevant Fortran kind type-parameters frequently used in the ParaMonte librar...
integer, parameter RK
The default real kind in the ParaMonte library: real64 in Fortran, c_double in C-Fortran Interoperati...
integer, parameter IK
The default integer kind in the ParaMonte library: int32 in Fortran, c_int32_t in C-Fortran Interoper...
integer, parameter SK
The default character kind in the ParaMonte library: kind("a") in Fortran, c_char in C-Fortran Intero...
This module contains procedures and generic interfaces relevant to generating and initializing matric...
This module contains procedures and generic interfaces relevant to combined matrix-matrix or matrix-v...
This is the class for creating benchmark and performance-profiling objects.
Example Unix compile command via Intel ifort compiler ⛓
3ifort -fpp -standard-semantics -O3 -Wl,-rpath,../../../lib -I../../../inc main.F90 ../../../lib/libparamonte* -o main.exe
Example Windows Batch compile command via Intel ifort compiler ⛓
2set PATH=..\..\..\lib;%PATH%
3ifort /fpp /standard-semantics /O3 /I:..\..\..\include main.F90 ..\..\..\lib\libparamonte*.lib /exe:main.exe
Example Unix / MinGW compile command via GNU gfortran compiler ⛓
3gfortran -cpp -ffree-line-length-none -O3 -Wl,-rpath,../../../lib -I../../../inc main.F90 ../../../lib/libparamonte* -o main.exe
Postprocessing of the benchmark output ⛓
3import matplotlib.pyplot
as plt
8dirname = os.path.basename(os.getcwd())
12df = pd.read_csv(
"main.out", delimiter =
", ")
13colnames = list(df.columns.values)
19ax = plt.figure(figsize = 1.25 * np.array([6.4,4.6]), dpi = 200)
22for colname
in colnames[1:]:
23 plt.plot( df[colnames[0]].values
28plt.xticks(fontsize = fontsize)
29plt.yticks(fontsize = fontsize)
30ax.set_xlabel(colnames[0], fontsize = fontsize)
31ax.set_ylabel(
"Runtime [ seconds ]", fontsize = fontsize)
32ax.set_title(
" vs. ".join(colnames[1:])+
"\nLower is better.", fontsize = fontsize)
36plt.grid(visible =
True, which =
"both", axis =
"both", color =
"0.85", linestyle =
"-")
37ax.tick_params(axis =
"y", which =
"minor")
38ax.tick_params(axis =
"x", which =
"minor")
39ax.legend ( colnames[1:]
46plt.savefig(
"benchmark." + dirname +
".runtime.png")
52ax = plt.figure(figsize = 1.25 * np.array([6.4,4.6]), dpi = 200)
55plt.plot( df[colnames[0]].values
56 , np.ones(len(df[colnames[0]].values))
61for colname
in colnames[2:]:
62 plt.plot( df[colnames[0]].values
63 , df[colname].values / df[colnames[1]].values
67plt.xticks(fontsize = fontsize)
68plt.yticks(fontsize = fontsize)
69ax.set_xlabel(colnames[0], fontsize = fontsize)
70ax.set_ylabel(
"Runtime compared to {}".format(colnames[1]), fontsize = fontsize)
71ax.set_title(
"Runtime Ratio Comparison. Lower means faster.\nLower than 1 means faster than {}().".format(colnames[1]), fontsize = fontsize)
75plt.grid(visible =
True, which =
"both", axis =
"both", color =
"0.85", linestyle =
"-")
76ax.tick_params(axis =
"y", which =
"minor")
77ax.tick_params(axis =
"x", which =
"minor")
78ax.legend ( colnames[1:]
85plt.savefig(
"benchmark." + dirname +
".runtime.ratio.png")
Visualization of the benchmark output ⛓
Benchmark moral ⛓
- The procedures under the generic interface setMatMulAdd are enhancements to the original BLAS routines.
However, they are currently not optimized for cache-efficient data access on various hardware.
Similarly, setMatMulAdd does not utilize blocking methods to improve cache access.
- For practical routine daily usages, setMatMulAdd offers a nice generic matrix multiplication interface.
However, the current implementations are suboptimal to hardware-tuned BLAS libraries such as OpenBLAS and MKL.
Such performance differences will be most striking for large matrices where cache-efficiency dominates the performance bottleneck.
- Test:
- test_pm_matrixMulAdd
- Todo:
- Critical Priority: The following BLAS Band-matrix routines must be added to this module:
-
SGBMV, DGBMV, CGBMV, and ZGBMV (Matrix-Vector Product for a General Band Matrix, Its Transpose, or Its Conjugate Transpose).
-
SSBMV, DSBMV, CHBMV, and ZHBMV (Matrix-Vector Product for a Real Symmetric or Complex Hermitian Band Matrix).
-
STBMV, DTBMV, CTBMV, and ZTBMV (Matrix-Vector Product for a Triangular Band Matrix, Its Transpose, or Its Conjugate Transpose).
Final Remarks ⛓
If you believe this algorithm or its documentation can be improved, we appreciate your contribution and help to edit this page's documentation and source file on GitHub.
For details on the naming abbreviations, see this page.
For details on the naming conventions, see this page.
This software is distributed under the MIT license with additional terms outlined below.
-
If you use any parts or concepts from this library to any extent, please acknowledge the usage by citing the relevant publications of the ParaMonte library.
-
If you regenerate any parts/ideas from this library in a programming environment other than those currently supported by this ParaMonte library (i.e., other than C, C++, Fortran, MATLAB, Python, R), please also ask the end users to cite this original ParaMonte library.
This software is available to the public under a highly permissive license.
Help us justify its continued development and maintenance by acknowledging its benefit to society, distributing it, and contributing to it.
- Copyright
- Computational Data Science Lab
- Author:
- Amir Shahmoradi, Friday 1:54 AM, April 21, 2017, Institute for Computational Engineering and Sciences (ICES), The University of Texas, Austin, TX